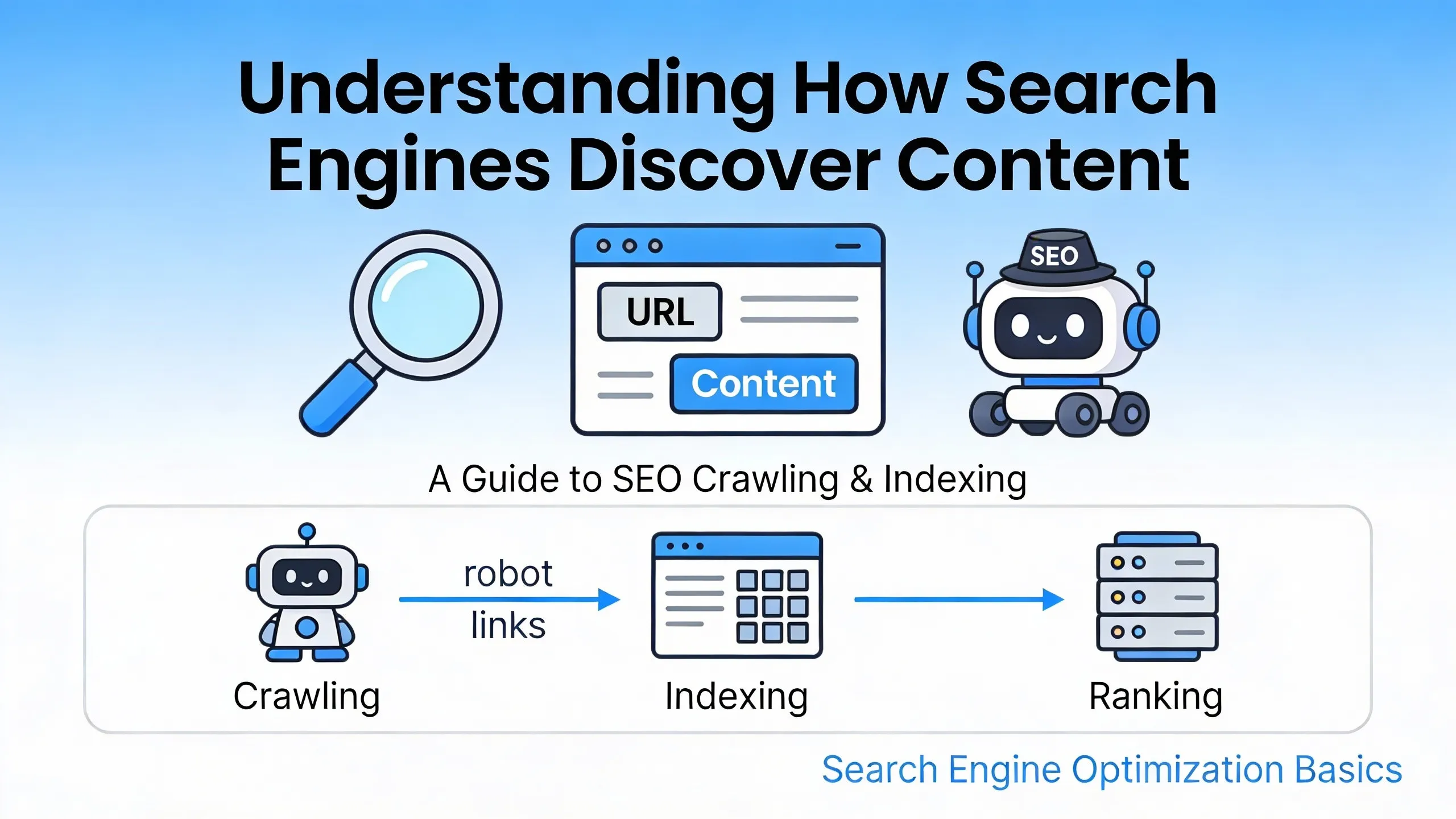
# Understanding How Search Engines Discover Content
Search engines are built to organize vast amounts of information and deliver the most relevant results to users in seconds. At the core of this process are three interconnected systems: crawling, indexing, and search visibility. Together, they determine whether a webpage exists in a search engine’s ecosystem at all, how it is understood, and how easily users can find it. While these concepts are often mentioned together, each plays a distinct role in how content moves from publication to ranking.
To fully grasp search performance, it helps to understand not just what these systems do individually, but how they interact. A technically sound website with strong content can still struggle if one part of this chain breaks down.
### What Crawling Really Means
Crawling is the discovery phase of search engines. Automated programs, commonly called bots or spiders, move across the web by following links from one page to another. When a new page is published or an existing one is updated, it must first be discovered through crawling before anything else can happen.
Crawlers operate with limited resources, meaning they prioritize certain pages over others. Factors such as site structure, internal linking, page load speed, and server reliability influence how often and how deeply a site is crawled. Pages that are buried deep within a site or poorly linked may be crawled infrequently, which can delay their appearance in search results.
Crawling does not evaluate quality in the way rankings do. Instead, it is about access. If a crawler cannot reach a page due to broken links, restrictive directives, or technical errors, that page effectively does not exist to the search engine.
### How Indexing Transforms Pages into Data
Once a page has been crawled, the next step is indexing. Indexing is the process of analyzing and storing information about a page so it can be retrieved later in response to a search query. During this phase, the search engine interprets the content, structure, and context of the page.
Text, headings, images, internal links, and metadata all contribute to how a page is indexed. The goal is to understand what the page is about and which queries it might be relevant for. Pages with unclear structure or thin content can be indexed poorly, even if they are crawled regularly.
Indexing is also selective. Not every crawled page is guaranteed to be indexed. Duplicate content, low-value pages, or URLs that appear redundant may be ignored or deprioritized. This is why having a clear content purpose for every page is essential.
### The Relationship Between Crawling and Indexing
Crawling and indexing are often spoken about together, but they serve different purposes. Crawling is about discovery, while indexing is about comprehension. A page must be crawled before it can be indexed, but being crawled does not guarantee successful indexing.
This distinction is important when diagnosing visibility issues. If a page is not appearing in search results, the issue could be that it has not been crawled yet, or that it was crawled but deemed unsuitable for indexing. Each scenario requires a different solution, whether that involves improving internal links or enhancing content relevance.
Understanding this relationship helps clarify why some pages take longer to appear in search results, even after being published correctly.
### What Search Visibility Actually Represents
Search visibility is the outcome of crawling and indexing combined with ranking algorithms. It reflects how prominently a page appears in search results for relevant queries. Visibility is influenced by hundreds of factors, but none of them matter if the page is not indexed.
High search visibility means a page is not only indexed but also considered relevant and authoritative enough to appear near the top of results. Low visibility often indicates weak signals, such as poor content alignment, limited authority, or insufficient connections to the wider web.
Importantly, visibility is not static. It changes as content is updated, competitors publish new pages, and search engines refine their algorithms.
### The Role of Links in Discovery and Indexing
Links are the pathways that crawlers use to navigate the web. Internal links help search engines understand site structure and page importance, while external links act as signals of credibility and relevance.
When a page receives links from other sites, it becomes easier for crawlers to discover it. These links also help contextualize the page during indexing by providing clues about how others perceive its content. Pages with no incoming links can still be indexed, but they are more likely to be overlooked or delayed.
Because of this, ensuring that important pages are properly linked both internally and externally plays a critical role in consistent indexing and long-term visibility.
### Why Some Pages Struggle to Get Indexed
There are many reasons why a page might not be indexed, even if it exists and is technically accessible. Poor content quality, duplication, unclear intent, and weak internal linking can all contribute to indexing issues.
Search engines aim to provide value to users, so they are cautious about storing pages that do not add anything new or useful. If a page closely resembles many others already indexed, it may be excluded to preserve index efficiency.
In competitive niches, this problem becomes more pronounced. Pages must demonstrate distinct value to earn their place in the index and maintain visibility over time.
### Accelerating the Path from Publication to Visibility
One of the challenges website owners face is the delay between publishing content and seeing it appear in search results. While this delay is normal, there are ways to encourage faster discovery and indexing.
Strong internal linking from already indexed pages helps crawlers find new content more quickly. External links can further reinforce discovery signals and highlight the importance of a page within a broader context. This is where indexing-focused solutions come into play. Tools such as[ backlinksindexer](https://linkindexer.io/) are often used to support the discovery of inbound links, helping search engines notice connections that might otherwise take longer to register.
Used strategically, this approach can help ensure that valuable links contribute to indexing efficiency rather than remaining unnoticed.
### How Indexing Impacts Ranking Potential
Indexing is not just a gateway to visibility; it directly affects ranking potential. A well-indexed page has clearly defined topical signals, making it easier for search engines to match it with relevant queries.
Pages that are partially indexed or misunderstood may rank for unintended terms or fail to rank at all. Clear headings, logical structure, and focused content help guide the indexing process, which in turn supports stronger ranking performance.
This is why technical optimization and content strategy must work together. Neither can compensate entirely for weaknesses in the other.
### Maintaining Long-Term Search Visibility
Search visibility is not achieved once and then locked in permanently. Over time, content can lose relevance, links can disappear, and competitors can overtake existing rankings. Maintaining visibility requires ongoing attention to both technical health and content quality.
Regular updates signal freshness, while consistent internal linking reinforces page importance. Monitoring indexing status and crawl behavior helps identify issues early, before they result in lost traffic.
Websites that treat crawling and indexing as ongoing processes rather than one-time concerns are better positioned to adapt to changes in search behavior and algorithm updates.
### Bringing It All Together
Crawling, indexing, and search visibility form a continuous cycle rather than a linear checklist. Crawling enables discovery, indexing enables understanding, and visibility reflects how successfully a page competes for attention in search results.
By understanding the science behind these processes, website owners can make more informed decisions about structure, content, and promotion. Instead of focusing solely on rankings, addressing the foundational mechanics that support them leads to more stable and sustainable search performance over time.
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://eztalks.gitbook.io/blog/growth/understanding-how-search-engines-discover-content.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.